Download
You can download the data from your crawls and use it for your custom data analysis.
| Table |
Fields |
Description |
domains |
domain 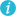 link count visit count page count relevance popularity |
Distinct domains found in parsed URLs. Our algorithms are tuned to rapidly discover the most relevant and popular domains in the niche. Our combined metrics which depend on many signals is successful in positioning domains in their right positions very early in the crawl. Of course this positions change as crawl statistics are updated, but it is quite robust in well connected topics, regardless of initial seeds provided. |
urls |
id url urlhash score pagerank referring domains external backlinks lang filtered near_duplicate wrong_lang not_on_topic error on_topic last_visit |
All likely relevant URLs parsed on visited pages. After being visited, they are further marked as on_topic, not_on_topic, error, etc. The better the crawl settings, the lower percent of false positives will occur, and link analysis tools will yield more useful results. filtered URLs are those that were blocked by forbidden sites, forbidden href patterns or forbidden atext patterns. |
graph |
parentid childid atext nofollow semantic flow ™ |
Graph edges of the crawled web where each parent or child id relates to id from urls table. Numerous experiments show that nofollow attribute is obsolete, but we provide it as some users ask for it. |
topic pages |
url urlhash relevance hubness title microdata lang links rel links new rel links external links external domains referring domains external backlinks main image url last_change |
Detected on-topic pages from visited URLs. For seed only crawls, hubness is a useful measure of proportion of new relevant links on the page since the last crawl. |
topic pages content |
url content plaintext summary |
We tried to extract the main content of a page, both in HTML and plain text format. Full HTML of on-topic pages can also be provided if you need more than just core content of web pages. We also provide an experimental summary for English language, or most important sentences for other languages. |