Topical SEO
Q: Why another SEO tool?
A: It is an obvious and useful application of our topical crawling infrastructure.
Thought experiment
A simple thought experiment will illustrate quite clearly the elusive yet obvious detail about the entanglement of importance and relevance. Imagine two pages, P1 and P2, which are exactly the same, and on topic T. For the sake of A/B testing, we pretend that we vary only a single parameter, which we will explain soon. So let us neglect for the moment the effect of duplicate content on their ranking, and pretend such effect does not exist when ranking pages. Now imagine these two pages have exactly the same incoming link profiles, of which none of the source pages is on topic T, except for S1 and S2, which are on topic T and exactly the same. Further imagine that PageRank of S1 is half the PageRank of S2, but that this difference in PageRank has been compensated by some opposite difference from two other souce pages on another topic, O1 and O2. Now if we have other two target pages P1' and P2' exactly the same to each other, where P1 links to P1' and P2 links to P2', and both links have the same word related to the topic T, lets say 'tword'.
Only pages in the graph on topic T are S1, P1, P1', S2, P2, P2'
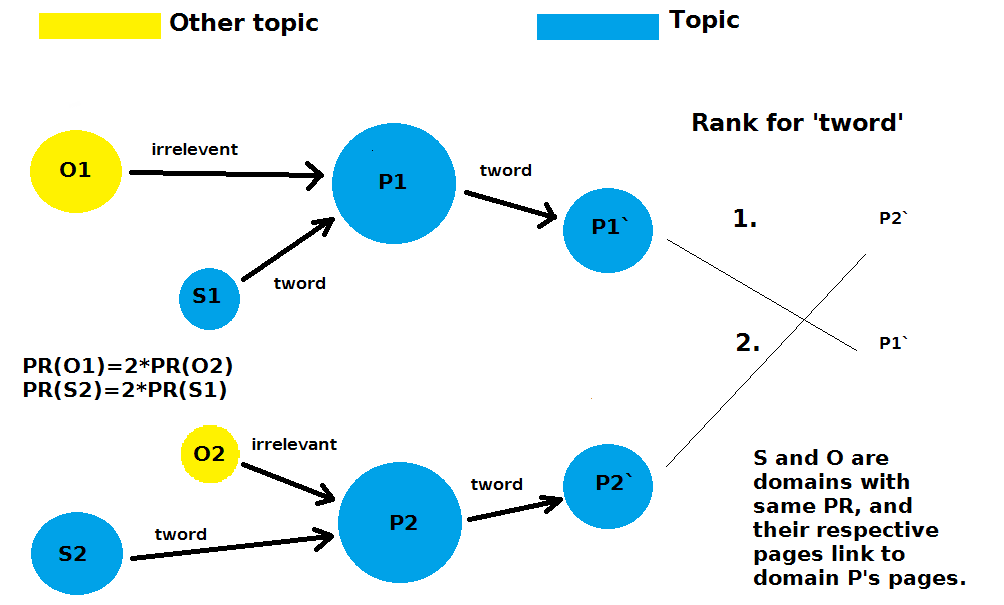
Which page, P1' or P2' will rank higher in search engine for the given query phrase 'tword'? Remember that every possible parameter is the same, only PageRank for the topic T and word 'tword' being received by P2 is higher than that received by the P1, because their topical PageRanks originate from S2 and S1 respectively. As you can see with this simple thought experiment, it is quite silly to assume that two pages having thousand incoming links each with atext 'tword' will be comparable, if those pages linking to them differ in pagerank and/or topic significantly! So those kind of stats, even though cool, are not showing us the most useful information, that is, which of all those links should we pay attention to. In other words, high PageRank page, even though on topic, may not have inhereted high topical PageRank, and there may be lower PageRank page that will transfer you more topical PageRank than this one! And not only that, some topical phrases may have much more Semantic Flow ™ than other topical phrases. You can spend less time on link aquisition by using your time more effectively.
Resources
Now, to show you that this is not just a thought experiment, but is based on sound research, we list here few of the relevant resources:
- Ranking Relevance in Yahoo Search
- Topical PageRank: A Model of Scientific Expertise for Bibliographic Search
- Phrase-based indexing in an information retrieval system
- 7 Illustrations of How Topical Links Impact Rankings, in Theory and Practice
- A Effective Algorithm for Web Mining Based on Topic Sensitive Link Analysis
- RANKING MUSIC DATA BY RELEVANCE AND IMPORTANCE
- Deep learning
- Topical Link Analysis for Web Search
- A New Entity Salience Task with Millions of Training Examples
- Teaching machines to read between the lines (and a new corpus with entity salience annotations)
- The TOPHITS Model for Higher-Order Web Link Analysis
- Andrew Ng: Deep Learning, Self-Taught Learning and Unsupervised Feature Learning
All best known SEO tools we have analyzed, judging by the information they provide to users, fail to measure the transfer of relevance in a meaningful way.
In fact, only one or two tools have tackled this problem at all. By doing this properly we provide an insight not available elsewhere. How do we know that what we measure is what is actually being done by search engines? Because topical link analysis is subject being researched for more than a decade now, and a few models of topical pagerank and transfer of relevancy have been developed, both using link structure of the web and semantic relatedness between text, anchor text, and target pages.
What most other tools are doing wrong?
They separate importance (authority) from relevance. This was justified long time ago, but for many years now it is simply not so. Maybe someone wrote about it from the SEO comunity, but we searched and read many many articles and couldn't find it. From major SEO blogs to IR blogs. Maybe some SEO professionals know what we are about to write but do not want to reveal it. In fact, we also thought few times before writing this article whether we should reveal it, as even though so obvious it seems to have eluded most. We decided that users need to know one of the reasons why this tool was build, besides the fact that we need this service for several of our own projects.
Above experiment and sources were provided to show that importance and relevance are not independent factors. Another thing to consider is how is this relevance calculated?
How machine knows what is relevant
Some SEO consultants did not quite understand it completely: "The link anchor for your landing page has to be relevant and emerge from a website that has the same theme as yours..."
While others got it quite right: "Search engines consider the overall relevance of the linking site, the relevance of the specific page with the link on it, and the relevance of the content directly surrounding the link."
There are articles and research papers which suggest dividing the whole web into smaller or larger, but finite number of topics. The only SEO tool we know was solving this problem uses this model. In our view these were prototypes that showed proof of the concept, but reality is that human knowledge is immense, and that to be meaningful categorized it would require huge number of categories. Open Directory has over one million categories. New knowledge is being created daily and therefore new categories should be added daily. Instead of having predefined categories, we believe search engines use well researched vector space and neural network models to detect if two contents are related, text and link anchor text and context for example. In layman terms, text is converted into numbers and high dimensional matrices are analyzed, vectorized content is being matched for similarity (SVM, LDA, NN, or similar) to solve natural language processing (NLP) problem of synonyms, similar and related concepts. This is exactly what much of the literature suggests, and is the model we implemented as well. When the web is categorized in limited number of categories, apparent relatedness between source and target page may not actually be that good. When you define your own topic, this similarity measure becomes more accurate as vectorized hyperplane is better defined, and compared context need to be more aligned to pass the threshold.
We do not have resources that search engines have and cannot analyze relevance for, nor crawl nearly as many pages, but have developed an efficient focused crawler that can crawl significant and most relevant portion of many niches within days. Some niches are too large and for those we are not yet sure whether recall is good enough, something for users to decide. Our classifier is trained on pages provided by user, and can therefore learn any abstract topic and co-occurrence of phrases as defined by those pages. The number of such topics will keep growing. There are some caveats though.
Does it work?
This is all very nice, but does it work? Like every other backlink analysis tool, this one also cannot reproduce what is actually happening inside Google. We can only look at some correlations between various backlink tools and Google results. Google has more than one hundred engineers working on core search for about two decades now, and thousands more engineers working in related areas whose results they incorporate into search. So no, 5-10 years we invested directly and indirectly into this project is only a fraction of time invested in the main search engine out there. Also, many of the information bits which influence rankings we do not even consider, i.e. clicktrough statistic, social media sharing statistics, etc.
Even if we used exactly the same algorithms which a search engine uses, we would also need exactly the same data for results to be reproduced, so about 100k servers for a web index and who knows how many servers for other data being stored and processed.
However, we have quite a bit of experience in both search engine development and Search Engine Optimization, and our insights have helped us to deduce some of the most important factors involved in SERP rankings. Sure there are hundreds of factors being considered in ranking pages, and hundreds of algorithms being applied from crawling to indexing and ranking, with all the knowledge graph, ontologies, natural language parsing, and other stuff involved. But it is fun to compare what we get after only few hundred thousand pages crawled, for a niche where people do understand a bit about ranking and are familiar with the top sites. Namely, explore the overview of a Search Engine Optimization niche, and tell us what you think about our results.
If you start with Google's results and use our Topical SEO approach explained above and implemented in our web crawler, you will find backlink opportunities which have clear advantage over results by other SEO backlink tools.